| back to Start | previous | next |
|---|
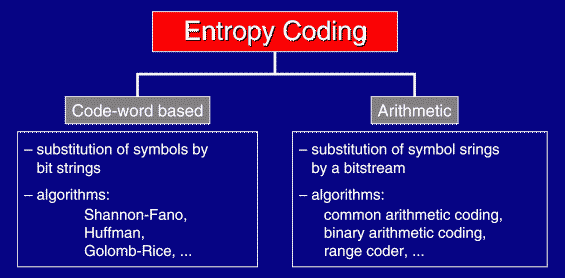
There are several algorithms to construct codes dependent on the statistical symbol distribution of the used alphabet, for instance Shannon-Fano coding or Huffman coding. Other algorithms use predefined code tables and switch between them, e.g. Golomb or Rice coding. Single symbols are substituted by single code words. These algorithms are called code-word based and the codes are also named as prefix codes, which is a short version of "prefix-free codes", concerning code words never being prefix of another code word.
The alternative to code-word based entropy coding is arithmetic coding. Such algorithms substitute complete strings of symbols with a single very long code word (bitstream).
The optimal compression is obtained if the storage expense (in bits) of a single symbol si is identical to its information content I(si). This fact implies that code-word based algorithms are merely sub-optimal, since always a whole number of bits is transmitted even if I(si) is fractional. Arithmetic coding overcomes this limitation.
| back to Start | back to Coding |
|---|